Kyle Brady of the University of St Andrews here expands on his popular presentation from our recent UKCoRR members day in the below post:
In July I attended the UKCoRR Members Day and delivered a presentation on the subject of approaching publishers for permission from the perspective of someone working in open access/repository support. The title of the presentation was ‘Requesting permission: approaching publishers, lessons learned, and the many successes!’ Here’s the presentation in the St Andrews Research Repository.
In this blog post I’ll go over some of the points from the presentation that I think struck a chord with the audience, with the overall intention of explaining the rationale behind our processes. Before I begin, I must say that I am very grateful to the other attendees on the day who shared their experiences in the Q&A, as well as after the event. It was really encouraging to hear from so many colleagues who have experienced similar stumbling blocks as we have, and it was especially useful to hear from those who do things differently to us at St Andrews.
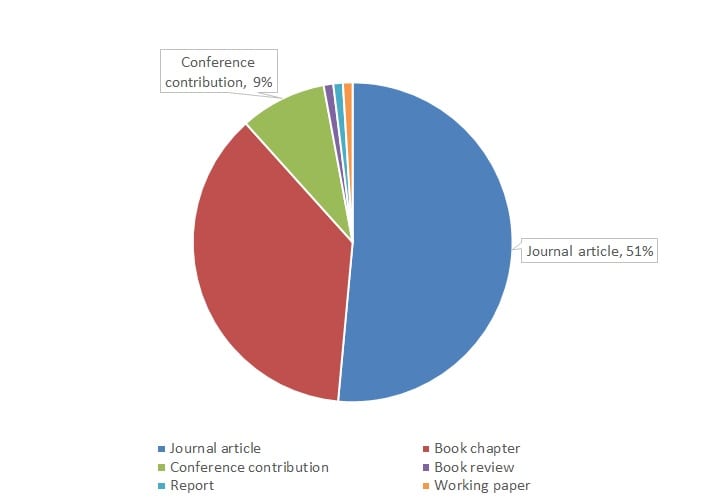
I had noticed the issue of publisher permissions popping up on the UKCoRR email list on a number of occasions, often in relation to specific publishers who don’t have a public open access or author self-archiving policy. Additionally, a Google Doc listing publishers and their responses to requests to archive book chapters has been circulated many times, and indeed was the subject of numerous discussions on the Members Day as well. This brings me to the first point from my presentation that I felt was perhaps the most illuminating, and this is the fact that most of our permission requests are actually for articles published in journals and conference proceedings. Perhaps not the most shocking expose on the face of it, but if you factor in REF2021 compliance it is in fact quite significant. This is because 60% of our permissions requests are for outputs potentially in scope for the REF open access policy. So, I argued, having an effective permissions policy can potentially affect an institution’s approach to their REF return and level of exceptions required.
Another perhaps less ‘sticky’ and more ‘carroty’ reason for all this comes down to effective curation of our research outputs. Many of the items in our repository are archived on the basis of successful permission requests for print-only publications, and so are often unique as they cannot be found online anywhere else. So, I explained my thoughts about digital preservation and the duty of care we have for this rare part of our collections. Part of this duty of care is ensuring permissions are well thought out, and that ensuing replies are clear and unambiguous. But, as I explained, no matter how careful you may be, I expect that risk management will always play a part in any decision to host third party copyright material online.
So, how do we do it? From the outset I want to state that I don’t believe our process is perfect by any means. And, although we have had an overwhelming amount of success there are caveats, but more on that later!
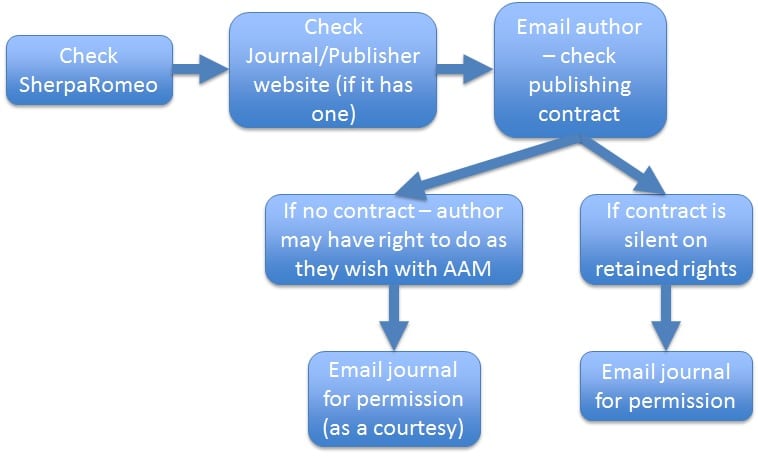
When we receive a manuscript for archiving we first check SherpaRomeo, an authoritative database of publishers’ and journals’ open access and author self-archiving policies that I’m sure we’re all intimately familiar with. If we come up short we then check the journal/publisher’s website for a policy (if indeed there is a website). If we are still left wanting we’ll then go to the author and ask them to check the publishing contract. This is a very important step as it includes the author in the process and in so doing alerts them to the work required to make things open access. It also has an important educational function as it highlights the importance of retaining rights, including copyright, and the distinction between exclusive and non-exclusive licences for instance. We are also conscious of the close relationship many of our authors have with publishers, so we always try to ensure that we have the author’s prior consent before any permission requests are sent.
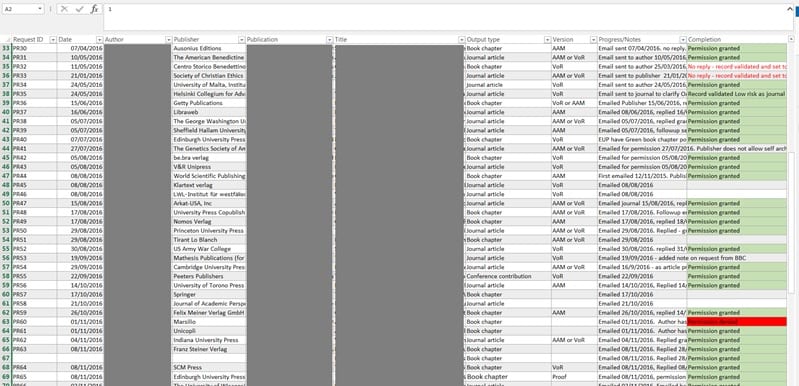
Once we have the go ahead to approach a publisher we record the action in a spreadsheet and assign it an ID. Then, when we receive a reply we can easily update the spreadsheet, take any actions on the Pure record (we use Pure as our Current Research Information System by the way!), and importantly we save the email in a folder and rename it according to the ID. We think it is important to track and document these requests in such a way as it creates a convenient audit trail, but it also gives us a way to assess the effectiveness of our process. You may also notice that we can report on the items types too, so for instance we know that 60% of our permission requests relate to outputs that are potentially in scope of the REF2021 open access policy.
The vast majority of responses come back in the form of emails, often but not always from editors of the journals themselves. As I said before these are filed away and retained as proof that permission has been attained. But, a question I posed at the end of my presentation was: does this actually protect our collection? It would seem common sense to suggest that items that are archived on the basis of an email are less protected than items that are archived in response to a signed letter. But is this actually the case? Might both forms of response be equally fallacious if in fact the issuer of the permission response is not vetted for authenticity (whatever that would mean). I don’t have an answer for this, so this is the point at which I ended my presentation and opened the debate to the floor.
My enduring impression from speaking to colleagues on the day was that each institution has a clear understanding of the level of risk they are willing to take, even if it is not enshrined in policy. Generally speaking my colleagues and I in the Open Access team at St Andrews tend to err on the side of caution and risk aversion, but from speaking to colleagues at other institutions my feeling is that we could perhaps afford to be less so. At any rate, the question of how we can protect these unique parts of our collections lingers on I’m afraid, and I suppose ultimately it is always going to be a balancing act between collection growth and collection sustainability.
If you’re a UKCoRR member and would like to contribute to the blog, please get in touch with any of us on the Committee.
Comments are closed.